 XXL-JOB分布式任务调度
XXL-JOB分布式任务调度
XXL-JOB分布式任务调度
一、什么是分布式任务调度
对一个视频的转码可以理解为一个任务的执行,如果视频的数量比较多,如何去高效处理一批任务呢?
1、多线程,多线程是充分利用单机的资源。
2、分布式加多线程,充分利用多台计算机,每台计算机使用多线程处理。
方案2可扩展性更强,方案2是一种分布式任务调度的处理方案。
什么是分布式任务调度?
思考: 我们可以先思考一下下面业务场景的解决方案:
- 每隔24小时执行数据备份任务;
- 12306网站会根据车次不同,设置几个时间点分批次放票;
- 某财务系统需要在每天上午10点前结算前一天的账单数据,统计汇总;
- 商品成功发货后,需要向客户发送短信提醒。
类似的场景还有很多,我们该如何实现?
1、多线程方式实现
我们可以开启一个线程,每sleep一段时间,就去检查是否已到预期执行时间。
public static void main(String[] args) {
//任务执行间隔时间
final long timeInterval = 1000;
Runnable runnable = new Runnable() {
public void run() {
while (true) {
//TODO:something
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
Thread thread = new Thread(runnable);
thread.start();
}
上面的代码实现了按一定的间隔时间执行任务调度的功能。Jdk也为我们提供了相关支持,如Timer、ScheduledExecutor,下边我们了解下。
Timer方式实现:
public static void main(String[] args){
Timer timer = new Timer();
timer.schedule(new TimerTask(){
@Override
public void run() {
//TODO:something
}
}, 1000, 2000); //1秒后开始调度,每2秒执行一次
}
Timer 的优点在于简单易用,每个Timer对应一个线程,因此可以同时启动多个Timer并行执行多个任务,同一个Timer中的任务是串行执行。
ScheduledExecutor方式实现:
public static void main(String [] agrs){
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
//TODO:something
System.out.println("todo something");
}
}, 1,
2, TimeUnit.SECONDS);
}
Java 5 推出了基于线程池设计的 ScheduledExecutor,其设计思想是,每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发执行的,相互之间不会受到干扰。
总结
Timer 和 ScheduledExecutor 都仅能提供基于开始时间与重复间隔的任务调度,不能胜任更加复杂的调度需求。比如,设置每月第一天凌晨1点执行任务、复杂调度任务的管理、任务间传递数据等等。
2、第三方Quartz方式实现
Quartz 是一个功能强大的任务调度框架,项目地址,它可以满足更多更复杂的调度需求,Quartz 设计的核心类包括 Scheduler, Job 以及 Trigger。
其中,Job 负责定义需要执行的任务,Trigger 负责设置调度策略,Scheduler 将二者组装在一起,并触发任务开始执行。
Quartz支持简单的按时间间隔调度、还支持按日历调度方式,通过设置CronTrigger表达式(包括:秒、分、时、日、月、周、年)进行任务调度。
下边是一个例子代码:
public static void main(String [] agrs) throws SchedulerException {
//创建一个Scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//创建JobDetail
JobBuilder jobDetailBuilder = JobBuilder.newJob(MyJob.class);
jobDetailBuilder.withIdentity("jobName","jobGroupName");
JobDetail jobDetail = jobDetailBuilder.build();
//创建触发的CronTrigger 支持按日历调度
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName", "triggerGroupName")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?"))
.build();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
}
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext){
System.out.println("todo something");
}
}
通过以上内容我们知道了什么是任务调度,任务调度所解决的问题,以及任务调度的多种实现方式。
总结
任务调度顾名思义,就是对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。
3、分布式任务调度
通常任务调度的程序是集成在应用中的,比如:优惠卷服务中包括了定时发放优惠卷的的调度程序,结算服务中包括了定期生成报表的任务调度程序,由于采用分布式架构,一个服务往往会部署多个冗余实例来运行我们的业务,在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度,如下图:
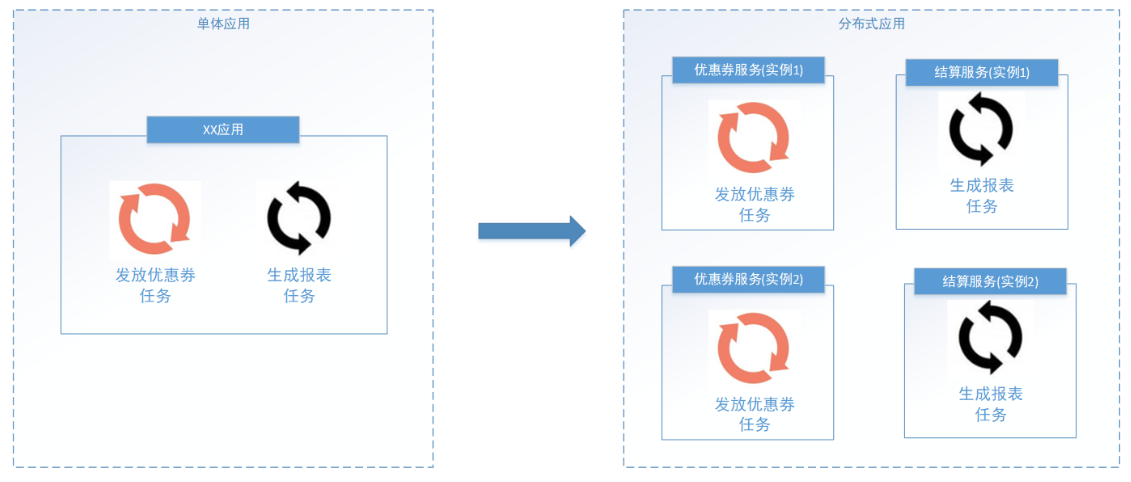
分布式调度要实现的目标:
不管是任务调度程序集成在应用程序中,还是单独构建的任务调度系统,如果采用分布式调度任务的方式就相当于将任务调度程序分布式构建,这样就可以具有分布式系统的特点,并且提高任务的调度处理能力:
1、并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,由不同的实例并行执行,来提高任务调度的处理效率。
2、高可用 若某一个实例宕机,不影响其他实例来执行任务。
3、弹性扩容 当集群中增加实例就可以提高并执行任务的处理效率。
4、任务管理与监测
- 对系统中存在的所有定时任务进行统一的管理及监测。让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
5、避免任务重复执行
- 当任务调度以集群方式部署,同一个任务调度可能会执行多次,比如在上面提到的电商系统中到点发优惠券的例子,就会发放多次优惠券,对公司造成很多损失,所以我们需要控制相同的任务在多个运行实例上只执行一次。
二、XXL-JOB
1、介绍
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
XXL-JOB主要有调度中心、执行器、任务:
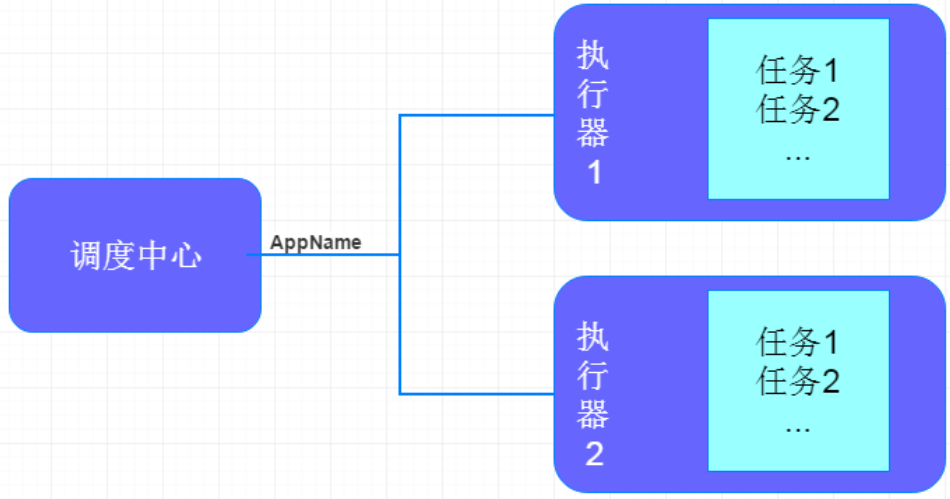
调度中心:
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码;
- 主要职责为执行器管理、任务管理、监控运维、日志管理等
任务执行器:
- 负责接收调度请求并执行任务逻辑;
- 只要职责是注册服务、任务执行服务(接收到任务后会放入线程池中的任务队列)、执行结果上报、日志服务等
任务: 负责执行具体的业务处理。
调度中心与执行器之间的工作流程如下:
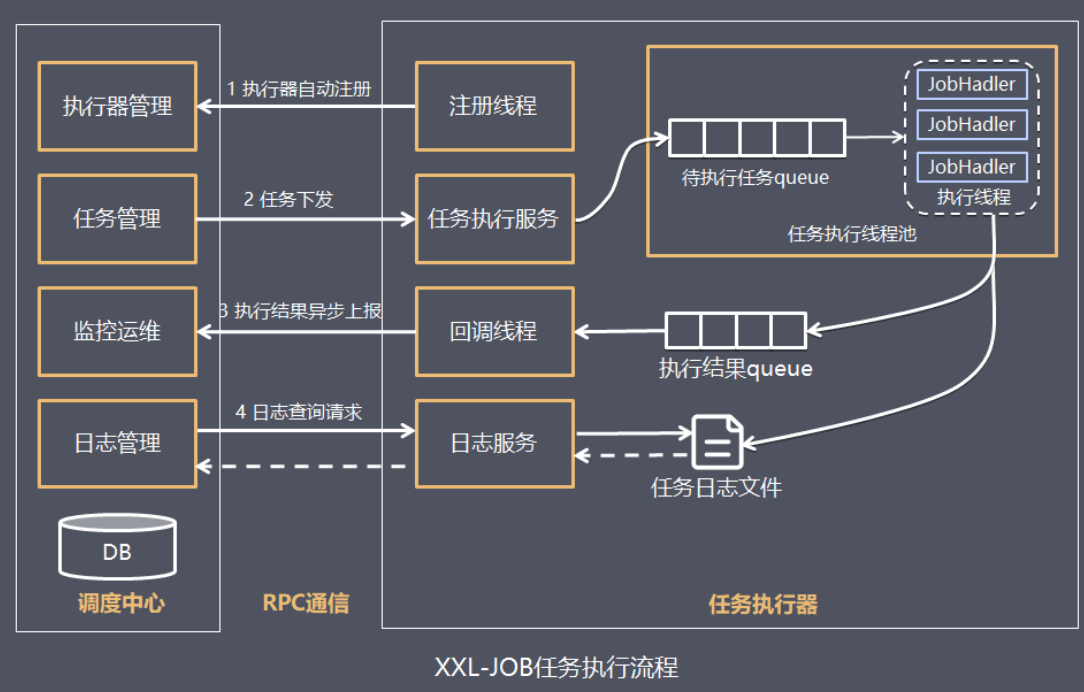
执行流程
1.任务执行器根据配置的调度中心的地址,自动注册到调度中心
2.达到任务触发条件,调度中心下发任务
3.执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
4.执行器消费内存队列中的执行结果,主动上报给调度中心
5.当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
2、搭建XXL-JOB
1)安装
首先下载XXL-JOB:
相关信息
xxl-job-admin :调度中心
xxl-job-core :公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用)
->xxl-job-executor-sample-springboot :Springboot版本,通过Springboot管理执行器,推荐这种方式;
->xxl-job-executor-sample-frameless :无框架版本;
doc :文档资料,包含数据库脚本
注意
部署之前需要现在数据库中运行doc中的数据库脚本创建数据库
使用docker部署:
docker run -d \
-e PARAMS="--spring.datasource.url=jdbc:mysql://${mysql}:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 --spring.datasource.username=root --spring.datasource.password=123" \
-p 8088:8080 \
-v /root/xxl-job:/data/applogs \
--name xxl-job \
--privileged=true \
--network hm-net \
xuxueli/xxl-job-admin:2.3.1
访问:http://localhost:8088/xxl-job-admin/
账号和密码:admin/123456
如果无法使用虚拟机运行xxl-job可以在本机idea运行xxl-job调度中心。
2)配置执行器
下边配置执行器,执行器负责与调度中心通信接收调度中心发起的任务调度请求。
1、下边进入调度中心添加执行器
点击新增,填写执行器信息,appname是后边在nacos中配置xxl信息时指定的执行器的应用名。
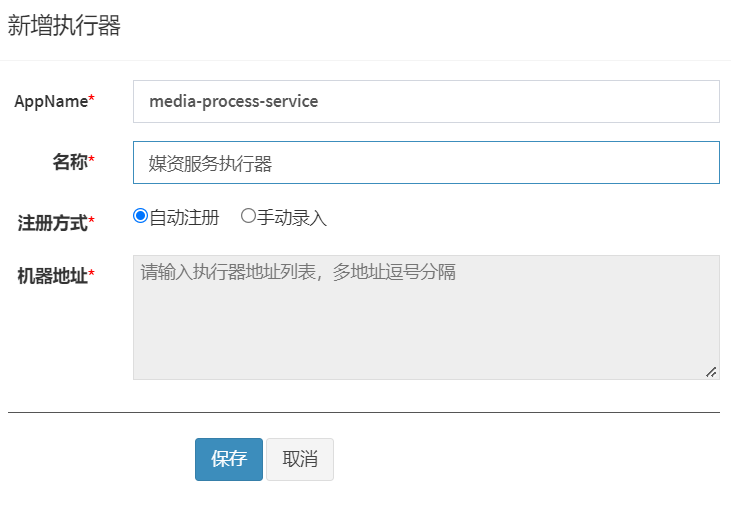
3)执行器
依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
在nacos下的media-service-dev.yaml下配置xxl-job
xxl:
job:
admin:
addresses: http://localhost:8088/xxl-job-admin
executor:
appname: media-process-service
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token
注意
配置中的appname这是执行器的应用名,port是执行器启动的端口,如果本地启动多个执行器注意端口不能重复。
将xxl-job示例工程下配置类拷贝到媒资管理的service工程下
package com.xuecheng.media.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author xuxueli 2017-04-28
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
之后准备测试执行器与调度中心是否正常通信,因为接口工程依赖了service工程,所以启动媒资管理模块的接口工程。启动后观察日志,出现xxl-job registry success日志表示执行器在调度中心注册成功
3、执行任务
在媒资服务service包下新建jobhandler存放任务类,下边参考示例工程编写一个任务类
package com.xuecheng.media.service.jobhandler;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
@Component
@Slf4j
public class SampleJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("testJob")
public void testJob() throws Exception {
log.info("开始执行.....");
}
}
下边在调度中心添加任务,进入任务管理,点击新增,填写任务信息
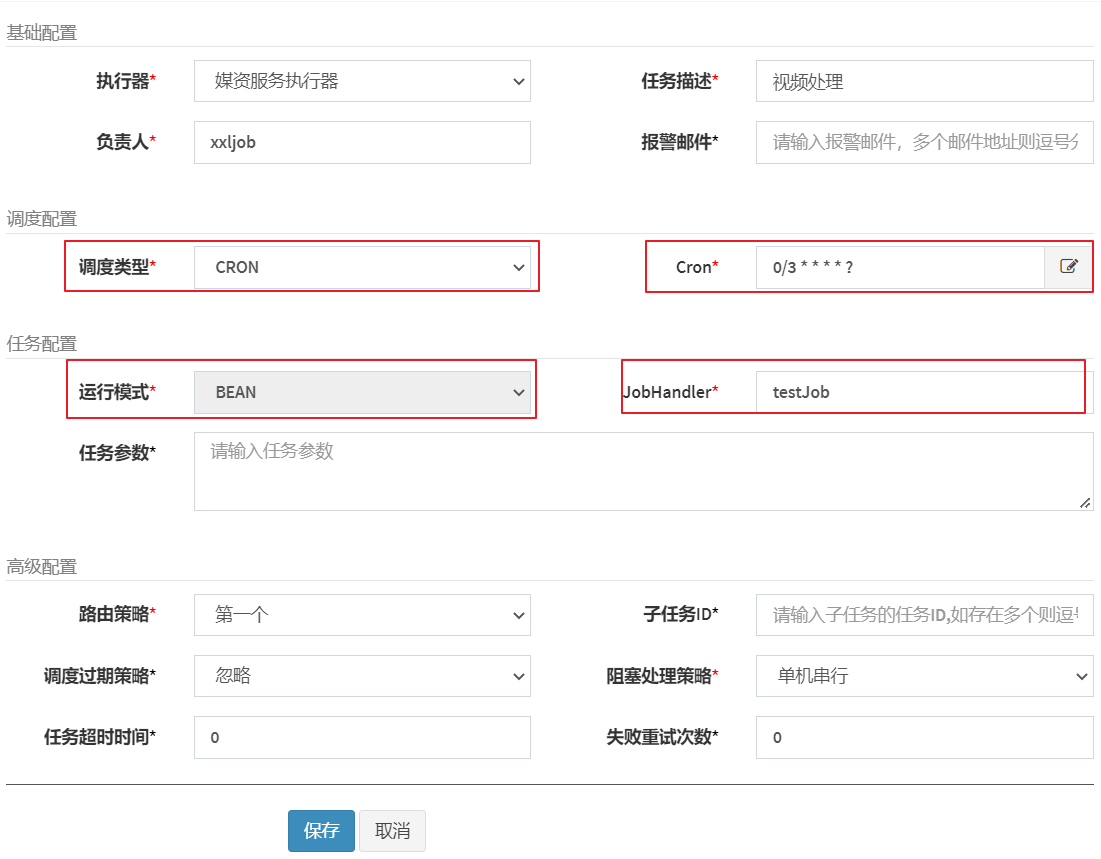
注意红色标记处:
- 调度类型:
固定速度指按固定的间隔定时调度。
Cron,通过Cron表达式实现更丰富的定时调度策略。
- Cron表达式是一个字符串,通过它可以定义调度策略,格式:
{秒数} {分钟} {小时} {日期} {月份} {星期} {年份(可为空)}
- Cron表达式是一个字符串,通过它可以定义调度策略,格式:
JobHandler即任务方法名,填写任务方法上边@XxlJob注解中的名称。
路由策略:当执行器集群部署时,调度中心向哪个执行器下发任务,这里选择第一个表示只向第一个执行器下发任务,路由策略的其它选项稍后在分片广播章节详细解释。
4、分片广播
如何进行分布式任务处理呢?,我们会启动多个执行器组成一个集群,去执行任务。执行器在集群部署下调度中心有哪些路由策略呢?
查看xxl-job官方文档,阅读高级配置相关的内容:
高级配置:
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度,通过子任务可以实现一个任务执行完成去执行另一个任务。
- 调度过期策略:
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
下边要重点说的是分片广播策略,分片是指是调度中心以执行器为维度进行分片,将集群中的执行器标上序号:0,1,2,3...,广播是指每次调度会向集群中的所有执行器发送任务调度,请求中携带分片参数。
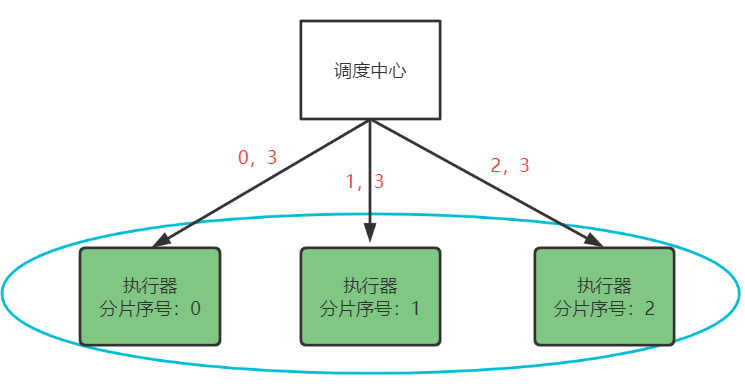
每个执行器收到调度请求同时接收分片参数。
重要
xxl-job支持动态扩容执行器集群从而动态增加分片数量,当有任务量增加可以部署更多的执行器到集群中,调度中心会动态修改分片的数量。
作业分片适用哪些场景呢?
- 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
- 广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等。
所以,广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群分布式处理任务。
使用说明:
"分片广播" 和普通任务开发流程一致,不同之处在于可以获取分片参数进行分片业务处理。
Java语言任务获取分片参数方式:
BEAN、GLUE模式(Java),可参考Sample示例执行器中的示例任务"ShardingJobHandler":
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片序号,从0开始
int shardIndex = XxlJobHelper.getShardIndex();
// 分片总数
int shardTotal = XxlJobHelper.getShardTotal();
....
将media-service启动两个实例来测试分片广播
两个实例的在启动时注意端口不能冲突:
实例1 在VM options处添加:-Dserver.port=63051 -Dxxl.job.executor.port=9998
实例2 在VM options处添加:-Dserver.port=63050 -Dxxl.job.executor.port=9999